Página 1 de 2
UTF-8
Enviado: 17 Set 2019 18:36
por JoséQuintas
Lembrei do arquivo do governo, e fui dar uma olhada.
Ele não usa acentuação nenhuma.
40 milhões de registros, 100GB
Em UTF-8, poderia aumentar pra 600GB.
600GB de importação em txt.... mais a base de gravação... e talvez temporários... e mais nossa base anterior....
3GB de disco? E tempo de processamento?
Uma simples atualização trimestral em UTF-8... acho que ainda não temos máquina suficiente pra processar isso em UTF-8.
Não tinha pensado nisso antes. É muuuito interessante.
Esse é um arquivo REAL, disponível trimestralmente pela Receita Federal.
O mesmo deve acontecer com Bancos, e outras empresas com muita informação.
Depois dessas contas, a conclusão é que UTF-8 só serve pra empresinhas pequenininhas, ou pra sites, ou pra coisas pequenas. Ou empresas gigantescas, que tem super computadores.
UTF-8 é o futuro?
Sim... no futuro vamos ter máquina que consegue processar isso.
Alguém por aí já usa UTF-8, e poderia confirmar isso?
UTF-8
Enviado: 17 Set 2019 20:53
por Jairo Maia
JoséQuintas escreveu:Alguém por aí já usa UTF-8, e poderia confirmar isso?
Eu não uso, e como você já disse, também não entendo muito sobre UTF, mas apenas lembrando que existe também UTF-16 e UTF-32.
Apenas sei que caracteres especiais latinos (acentuados e cedilha) usam 2 bytes em UTF-8, 4 Bytes em UTF-16 e 8 Bytes em UTF-32. Acho que é isso.
Também sei que quando tudo passar a usar UTF-X terá também a tecnologia de compressão. Sem compressão acho que ficará impossível, ou terá que mudar a tecnologia de hardware também para suportar.
UTF-8
Enviado: 20 Set 2019 10:57
por Itamar M. Lins Jr.
Ola!
Até onde sei UTF e cia não aumenta arquivo, é só uma mascara para usar. As mascaras ficam nos leitores, e não nos arquivos.
Código: Selecionar todos
1 – Via cabeçalho HTTP
Content-Type: text/html; charset=utf-8
2 – Via Meta Tag
<!-- HTML 4 -->
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<!-- HTML5 -->
<meta charset="utf-8"/>
3 – Via XML
<?xml version="1.0" encoding="utf-8"?>
É apenas um identificador do texto, se o texto está em japonês não adianta usar mascara de português.
Saudações,
Itamar M. Lins Jr.
UTF-8
Enviado: 20 Set 2019 11:22
por JoséQuintas
UTF-8 usa de um a quatro bytes (estritamente, octetos) por carácter, dependendo do símbolo Unicode que representa. É necessário apenas um byte para codificar os 128 caracteres ASCII (Unicode U+0000 a U+007F). São necessários dois bytes para caracteres Latinos com diacríticos. São também usados dois bytes para representar caracteres dos alfabetos Grego, Cirílico, Armênio, Hebraico, Sírio e Thaana (Unicode U+0080 a U+07FF). São necessários três bytes para o resto do Plano Multilingual Básico (que contém praticamente todos os caracteres comuns utilizados). Existem ainda outros caracteres que necessitam de quatro bytes.
https://pt.wikipedia.org/wiki/UTF-8
No Harbour tem funções especiais pra lidar com UTF8
UTF-8
Enviado: 20 Set 2019 11:32
por JoséQuintas
Código: Selecionar todos
PROCEDURE Main
LOCAL cTexto := "éééééééééééé"
? cTexto
? Len( cTexto )
? hb_StrToUTF8( cTexto )
? Len( hb_StrToUTF8( cTexto ) )
Inkey(0)
RETURN
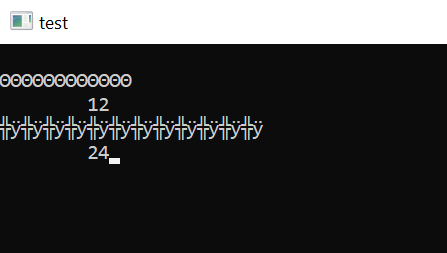
- utf8.png (2.92 KiB) Exibido 5458 vezes
Não usei PTBR, então a conversão foi de OEM pra UTF-8.
UTF-8
Enviado: 20 Set 2019 11:34
por JoséQuintas
Código: Selecionar todos
REQUEST HB_CODEPAGE_PTISO
PROCEDURE Main
LOCAL cTexto := "éééééééééééé"
Set( _SET_CODEPAGE, "PTISO" )
? cTexto
? Len( cTexto )
? hb_StrToUTF8( cTexto )
? Len( hb_StrToUTF8( cTexto ) )
Inkey(0)
RETURN
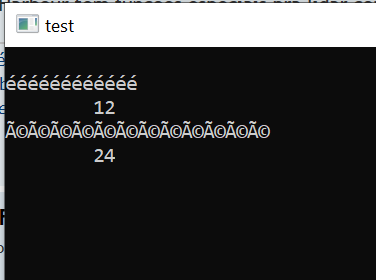
- utf8.png (4.48 KiB) Exibido 5457 vezes
Com PTISO.
UTF-8
Enviado: 20 Set 2019 11:37
por JoséQuintas
Núcleo Harbour (instalado):
hb_cdpIsUTF8()
hb_StrIsUTF8()
hb_StrToUTF8()
hb_utf8Asc()
hb_utf8At()
hb_utf8Chr()
hb_utf8Left()
hb_utf8Len()
hb_utf8Peek()
hb_utf8Poke()
hb_utf8RAt()
hb_utf8Right()
hb_utf8StrTran()
hb_utf8Stuff()
hb_utf8SubStr()
hb_UTF8ToStr()
hb_UTF8ToStrBox()
HB_CODEPAGE_UTF16LE()
HB_CODEPAGE_UTF8()
HB_CODEPAGE_UTF8EX()
Tem Asc(), At(), Chr(), Left(), Rat(), Right(), StrTran(), Stuff(), Substr(), etc. pra usar com UTF-8.
Ou seja... UTF-8 nem pensar ainda.
UTF-8
Enviado: 20 Set 2019 12:55
por JoséQuintas
Fiz um outro teste de curiosidade.
Desta vez o FONTE em UTF-8.
Note que a string original de 11 bytes subiu pra 22 bytes.
A conversão não é importante, apenas não retirei do fonte.
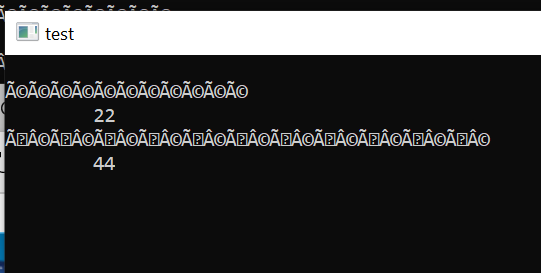
- utf82.png (5 KiB) Exibido 5450 vezes
UTF-8
Enviado: 20 Set 2019 12:59
por JoséQuintas
A última... tudo em UTF-8
11 letras retorna tamanho 22
UTF-8
Enviado: 20 Set 2019 13:08
por JoséQuintas
Lembrei do TYPE do prg:
Comprovadamente, UTF-8 aumenta o tamanho.
Como eu disse antes, uma coisa é página de internet, outra coisa é base de dados.
Difícil imaginar o computador trabalhando com tamanho desconhecido de caractere, sem precisar de processamento pesado.
Já estou pensando em como isso pode afetar a base MySQL, quando escolhemos salvar como UTF-8.
Podemos sobrecarregar o servidor sem nem perceber.
UTF-8
Enviado: 20 Set 2019 13:11
por JoséQuintas
Somente.
ANSI acaba sendo a codepage do Windows, que é PTBR.
Geralmente o programa é no nosso idioma, então não sei se precisaríamos de outra.
UTF-8
Enviado: 20 Set 2019 13:17
por JoséQuintas
Uma coisa leva à outra.
Windows PTBR, e PROMPT em EUA/USA/437/OEM sei lá qual.
Nesse caso o tamanho não muda, é só o problema de codepage que conhecemos.
UTF-8
Enviado: 20 Set 2019 18:11
por JoséQuintas
hazael escreveu:incluindo DOS (CP 437) que é o padrão do Clipper.
Eu já disse por aqui:
Na hora de trocar codepage, fiz todos os testes pra ver se ficava compatível.
PTISO deu os resultados certos.
Agora é tudo nessa codepage.
Só aqueles dois comandos, que já mudam tudo de uma vez.
REQUEST HB_CODEPAGE_PTISO
Set( _SET_CODEPAGE, "PTISO" )
Bateu com tudo que eu usava, então nunca mais usei nenhuma outra codepage.
Lembrando:
Console é codepage do console, Windows é codepage do Windows.
GTWVG parece console, mas usa janela Windows.
UTF-8
Enviado: 21 Set 2019 01:44
por JoséQuintas
hazael escreveu:Interessante, no VSC tem muitos, eu mesmo já usei no mínimo 4 diferentes em situações que foi necessário, incluindo DOS (CP 437) que é o padrão do Clipper.
Curioso em saber sobre as situações.
A do Clipper é a do DOS.
No Windows 10, até o prompt mudou e aceita até mesmo UTF-8
Acredito que comuns são apenas 4: CP437 do DOS/OEM/Clipper, PT-BR do Windows, Unicode também do Windows, UTF-8.
No Linux nem sei qual é, é algo não identificado, então uso sem acentos.
UTF-8
Enviado: 24 Set 2019 13:07
por Itamar M. Lins Jr.
Ola!
Código: Selecionar todos
function main
local cTxt:=""
set(_SET_CODEPAGE,"UTF8")
cTxt := "éÉçÇ"
? cTxt
? len(cTxt)
return nil
"É" esta em cp437, "É" em UTF8 é outra coisa.
Aqui retornou len() = 4, mostrou tudo errado no console. Como é o esperado.
Não adianta escrever em um idioma e converter. O acento e a letra são 2 mesmo.
Tem que mudar a pagina antes de chamar a mascara.
Já me bati muito com isso a Hwgui é compatível com UTF -> UNICODE (Código universal)
Saudações,
Itamar M. Lins Jr.